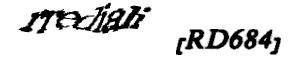About this graph
- This chart shows 240 of the total 251 valid tests.
Looking at the aggregates across all captchas, I tossed out the 3 users with: the fastest, slowest times, best and worse scores (11 total since 1 test fell into 2 categories).
- The captchas are in order as they were presented in the test (right-to-left). Everyone got captchas presented in the same order.
- No feedback was given if the captcha was answered correctly or not. The test just moved on to the next image.
- Accuracy is green and higher is better. Range goes from -1.0 -> 1.0 and is based on a fairly complex algorithm. (see Scoring Challenges section below).
- Time is blue and lower is better. It is measured in second from when the image finished loading until when the answer was submitted.
- mHkRvh is the first 4D captcha presented where the red line is drawn. (see Captchas Used in Test table below).
- There is a captcha missing from the results (nusMex géographie). This was a removed from the initial processing because the unicode character é was difficult to handle correctly using my tools. I will go back and try to re-add it. (See scoring discussion below.)
- I didn't include scores for people who didn't complete the whole test. I need to go back and figure out drop-off rates.
- For scoring, special characters, whitespace and case did not matter. (e.g. 'rrediali [RD684]' == 'rredialird648' == 'rrediali rd684')
- Accuracy score is a non-trivial calculation. This seems like a simple algorithm like (Letters Correct / Total Letters) a good measurement; however, there are some cases where it doesn't work very well. In particular, if a user mistakes two letters like 'rr' for a single letter like 'm'. Technically, this is a single mistake, but it is counted as two: an 'r' is missing and the other r is replaced by an 'm'. I have an alternate scoring approach below that tries to compensate for this form of mistake.
- This chart was created using Google Charts.
Scoring challenges
One interesting challenge was scoring "correctness" of an answer. The naive approach would be to just do a straight letter-by-letter comparison; however, if the user omits any character near the start of the answer, then the score looks worse than it really is.
Some examples, let's say the captcha is 'ABCDEF'
Answer: 'ABODEF'
One letter is incorrect in position #3
Answer: 'ABDEF'
Technically, only one letter is missing, but a character-by-character compare looks like 4 characters starting at C (e.g. 'CDEF')
This becomes even more complex for the rotating captchas were the user can start the answer anywhere.
Answer: 'CDEFAB' is 100% correct.
ABCDEF, just started typing at letter C
The next wrinkle happens when a user leaves out a character or inserts an extra one in addition to skewed starting locations:
Answer: 'DEFAB'
1 letter incorrect. C missing.
Answer: 'DEFABO'
1 letter incorrect. O vs C
Answer: 'CDEFABC'
Actually 100% correct, just starting typing loop over again! Not really a mistake for a looping captcha.
Answer: 'DEFAI3C'
1.5 letters incorrect. B was mistaken for an 'I3'. Technically, this is a single mistake, but two letters are wrong.
A mistake I struggled to deal with was when two letters is mistaken as one or vise versa. This happened for the standard captcha 'rrediali [RD684]' where many mistake the double r's as an m. It's really just one mistake, but a naive score would count it as two. What my score algorithm attempts to do is only penalize half for any missing or extra character. So in this case the score penalty is only 1.5 instead of 2.0
I've worked out algorithms to calculate scores for all these scenarios. I'm not convinced it's perfect, but it's a good start.
def calc_correctness_score(str1, str2):
# not very efficient, but we are only doing a few hundred tests
score = 0.0
correct = 0
str1len = len(str1)
str2len = len(str2)
shorterlen = min(str1len,str2len)
for jj in xrange(0, shorterlen):
if str1[jj] == str2[jj]:
score += 1.0
correct += 1
elif str1[jj] == '_' or str2[jj] == '_':
score -= 0.5 # missing or extra char is only 1/2 off.
else:
score -= 1.0
# now lower score by the delta in str lengths
delta = (max(str1len,str2len) - shorterlen)
score -= delta
correct -= delta
return round(score/len(str1), 2), correct, len(str1)
This function returns scores in the range of -1.0 through 1.0.
1.0 is perfect, 0.0 means as many characters correct as wrong, < 0 means more character incorrect than right.
This bit of code is also used to figure out the best alignment when looking for missing or extra characters in answer. The '_' character is used as a marker for a missing character. I wanted to weight incorrect characters more heavily than mistyped characters to improve this alignment. The scores kind of reflect this.
However, this technique also gives lower scores to much shorter captchas (so all the 4D captchas). For example, 2 mistyped characters 'rr' for rrediali [RD684] results in a score of 0.73 since it's 13 characters long. While 1 mistyped character for NyYP3r means an even lower score of 0.67.
Other measurements
The test tracked all keyboard and mouse events within the page. One interesting event was how often the user had to delete something they typed.
 |
| Number of times the delete key was pressed |
We can see the the "reediali [RD684]" and mHkRvh captchas gave people the most problems.
[edit 10Jan2011 9:22pm : David Jeske pointed out I missed an obvious captcha measurement. How many people pass versus fail a given test.]
Captcha
|
Correctly Answered
|
Percent Passed
|
|---|
fomeyingn
|
226
|
94.17%
|
euteouthen
|
157
|
65.42%
|
the eiveig
|
121
|
50.42%
|
rrediali [RD684]
|
129
|
53.75%
|
mHkRvh
|
187
|
77.92%
|
MpKsTH
|
170
|
70.83%
|
zeaBaP
|
213
|
88.75%
|
usPHVT
|
228
|
95.00%
|
NyYP3r
|
149
|
62.08%
|
Bephre
|
231
|
96.25%
|
Again, we see that, although 4D captchas are considered very difficult, their success rate is better than equivalently difficult traditional captchas did in this particular set of tests.
Traffic Info
People hate captchas... a lot. I get that.
When a user is trying to do something on a site, like remember their password or sign up for an account, being forced to solve a captchas is similar to having to find the right key to open a locked door. It's not their actual goal, but an obstacle stopping them from doing what they want. Being annoyed and disliking captchas is understandable. However, a lot of usability traffic came from people who are actively anti-captcha.
| What is your level of knowledge regarding Captchas? |
| 36 | Have a little knowledge of wavy letters used around the web. |
| 22 | Can spell Captcha correctly, but that's about it. |
| 159 | Already knew about Captchas and why they are required. |
| 63 | Know what C.A.P.T.C.H.A. stands for without looking at wikipedia. |
| 36 | Have designed/added support for Captchas on a website. |
| 6 | Have written code that mock current, weak Captchas! |
| Do you have any opinion about Captchas? |
| 26 |
Really hate them... no really. |
| 79 |
Find them annoying, but whatever. |
| 67 |
Accept them as a necessity and I floss daily. |
| 0 |
Understand the necessity, but feel they could be better implemented. |
| 19 |
Enjoy these Turing tests reaffirming my humanity. |
Post test questions about special conditions. Of the 241 tests used, 22 users indicated having some condition that it might have some effect on their results.
(ToDo: look at these user's scores and see how they compare to the average.)
Here's some screen shots from vappic.com's traffic during the usability tests.
John Foliot (who now works for JP Morgan Chase) posted a rant on his accessibly oriented blog about how evil the 4D captcha experiment is
:
The developer of this little bit of misery (an ex-Google employee no less – he should know better) has posted his email address (tomn@vappic.com) and so one thing you can do is write this guy and give him some appropriate type of feedback on this project: I’m not advocating an email equivalent of a DOS attack, but hearing from tens or hundreds or even thousands of end users encouraging him to go pursue another type of project might get his attention.
Irony is, DoS attacks are stopped by technologies such as captchas. Still, his little rant got reposted to other blogs and I think the users base was slightly skewed as a result. I welcomed the traffic though.
David Jeske sums up a reasonable point of view on captchas in his various
Vappic discussion group posts that reflect my feelings. The anti-captcha viewpoints are also listed on the site.
Some conclusions
Image parameters
When first designing the animated GIFs there were lots of decisions. How many frames are needed: 30, 60, 90? How fast should the animation be (fps)? What dimensions would be big enough? How many colors should the GIF have 4, 8, 32, 254 colors?
Each parameter effected the usability and file size of the images.
I did lots of random tests on a few friends and settled on something good enough for this test:
- 72 frames at 0.09 sec/frame (~ 11fps). Total playback duration is ~6.5sec.
- 200px x 150px (wide x tall)
- 4 colors mono (avoids color blindness issues)
It would be nice to do more usability tests to determine what combination of animated gif parameters is really ideal, but I don't have an unlimited pool of testers and I wanted to gather data related to people's first exposure to 4D captchas.
The choice of only using 4 colors was intentional. The thought is that fewer colors provides less information for OCR (computer based character recognition) to reverse engineer the model and guess the captcha.
Contrast was just too low on the GIF images. This was my fault. When generating the captchas in POV-Ray it's very difficult to control the image contrast. I've since found a solution in the post production phase when the images are turned into animated gifs.
Camera Movement
People complained about extreme camera movements. The Trig function SIN() used for camera movement has "bump" effect when it reaches the end of a cycle. It was a little too jarring.
However, while people complained about it, the scores seem better than ones with minimal camera movement.
I've tweaked the camera movement a bit in newer animations. POV-Ray code:
function(amp,decay) { amp*sin(localclock1*pi*2)/exp(decay*localclock1) }
Naturally, there is some variation with the camera movement to prevent
Unfamiliarity vs Usability
People quickly got better at 4D captchas with just a little bit of practice. The first 4D captcha took 25.69s and had an accuracy of only 0.892. By the 5th and last 4D captcha, that had improved to 10.92s and 0.988 accuracy.
The animated gif is only 6.5 seconds long, but the first letter doesn't come around until frame 24 (2.16s into animate). So, it seems likely that most people were able to type the captcha on the first rotation. Accuracy is on par with the easiest, standard captcha in the test. This one had a 0.987 accuracy and took 9sec to solve. It was the first captcha in the test, so we can assume the speed and accuracy might be lower because of its position.
(see Captchas used in test table below)
Low accuracy for NyYP3r captcha
NyYP3r captcha is interesting. We see a noticeable drop in accuracy and an an increase in time to type it.
My initial theories were:
1. Touch typists still need to look down a the keyboard to type the '3'
2. There is less camera movement in this 4D captcha than all the others
Here's a breakdown of the top answers for this captcha. Mistakes are in red.
| answer | score | count |
|---|
| nyyp3r | 1 | 156 |
| nvyp3r | 0.67 | 72 |
| nyypsr | 0.67 | 3 |
| nyyr3r | 0.67 | 2 |
Looking at the NyYP3r animation closer, you'll notice that the bottom part of the lower case 'y' rotates out of frame and is clipped. This might account for why so many people got this character wrong.
Table showing top answer clusters for each captcha.
Touch typists and rotating captchas
Lots of people mentioned loosing their place in the rotating captcha when they looked down at the keyboard.
This is a solvable problem by using a different 3D model; however, one solution someone found was to read the 4D captcha out loud as it spun, then typed the whole string into the answer box afterwards.
[edit: Here's a blog posting exploring some different 4D models that address this issue.]
References
Captchas used in test
Data
There is probably lots of other interesting conclusions that could be drawn from this first usability test. For example, one tester waited over 30seconds for images to download and display. Here's some of the test data that's been anonomized and processed:
Google Spreadsheet.
About making this test
I used several technologies when creating Vappic. The captcha images are rendering using Python and
POV-Ray, then turned into animated gifs using Python + ImageMagick + Gifsicle.
Server was written in Python for Google App Engine platform with heavy use of JQuery (javascript). I created a way to cheaply host a large number of huge images in GAE. I created an example project,
pis-demo to share how it was done..
Post processing used Python, Excel, Sql, some js based tools I wrote. One javascript based online tool has proved very useful for creating tables:
merge magic utility.
One of the biggest challenges was just bouncing between programming languages: POV-Ray rendering language, python, javascript, sql.
And naturally, one of the bigger pain-points was dealing with Internet Explorer. It ended up only being 3% of my users but a significant amount of work.